Supercomputer scrutinizes Finnish parliamentary elections
As social media like Facebook and Twitter become increasingly influential in the decision making of the voters, social scientists take an interest in scrutinizing, how discussions and debates emerge and evolve in the intersection between traditional media and social media. Finnish researchers have enlisted a supercomputer to crack the data.
1.5 million social media updates
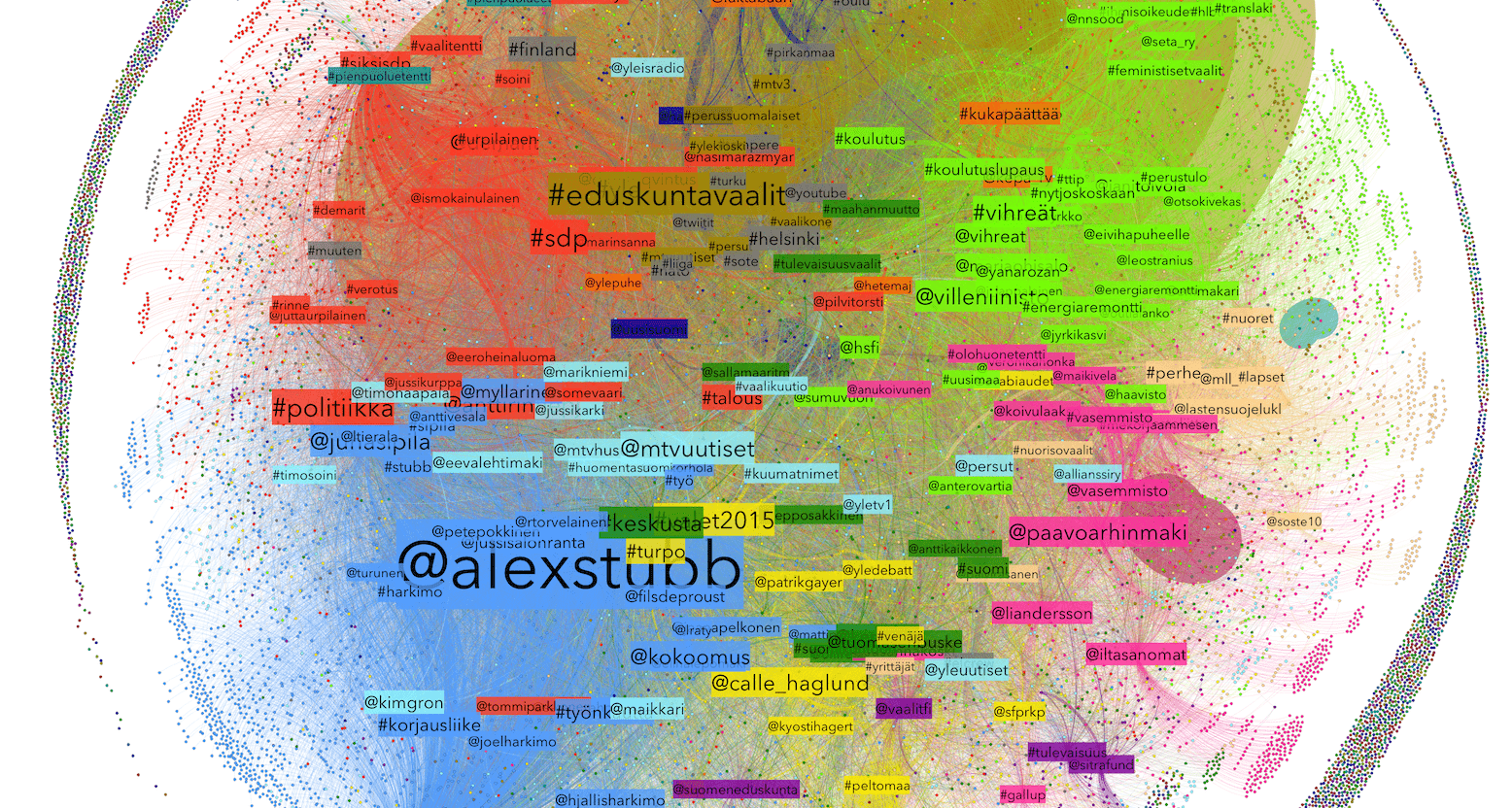
Named Digivaalit 2015 – the Digital Election 2015 – the research project has analysed 1.5 million social media updates as well as 7,500 news articles related to the Finnish parliamentary elections in the beginning of 2015. The complex task was performed by the Taito supercluster of Finnish research and education network CSC.
To find and follow discussion themes in these different media spheres the researchers used topic modelling, a statistical framework to discover “topics” in a collection of texts. A topic model is created by grouping words related to different topics, and based on the statistics of the words in each text you can examine each document’s balance of topics.
 Power structures
Power structures
We wanted to study the power structures and agenda building in digital media, and the relations between news media and social media, Salla-Maaria Laaksonen from the Communications Research Centre at the University of Helsinki explains.
Social media is often perceived as a whole new media sphere, where the traditional power structures in society are less relevant. Some experts have even argued, that social media dissolves these power structures and creates a whole new and more equal arena for political debate. We wanted to test these assumptions by analysing the ability of social media to affect what topics are present in public discussion. In other words: What is the agenda building power of social media?
We were able to build an “influencer index”, counting “influencer scores” for each election candidate, to establish a hierarchy among them. And we were able to identify the election’s “super influencers”. Only a handful of candidates have these high influencer scores and most candidates low.
In general, the study shows a close connection between the online sphere and traditional news media. Most of the super influencers have a strong presence in traditional media, but still we found a few being able to achieve high visibility by mainly using social media effectively.
Computational social science
Digivaalit 2015 is a project in a fairly new area – computational social science – where humanities researchers dive down into huge sets of digital data, using algorithms to uncover new knowledge. It’s a discipline that depends on strong cross-disciplinary cooperation.
We’ve combined social scientific research on communications and politics with big data analysis adopted from computer science. Along the way we developed some new methods of analysing the dynamics of digital and traditional media, and hopefully we are contributing to moving this promising new research forward.
Text crunching
Among other things, there are some specific challenges when you work with “text crunching” instead of “number crunching”. Most tasks performed on the Taito supercluster are about number crunching.
When it comes to text crunching, you extract data from different social media services, demarcate the actual research data you need from the raw data, and then divide the data into analyzable word tokens.
Next in order to do any analysis we need to lemmatize the words – that means to transform each to their base form. The Finnish language with its conjugations and special characters makes this a bit less straightforward than in English for instance.
All this preprocessing takes almost as much time as running the topic model. Plus a human interpreter needs to validate and check results produced by the computer in the all phases of the research, says Salla-Maaria Laaksonen, who is also participating in another computational social science project, analysing one of the largest non-English online discussion forums in the world, Suomi24.
A huge lump of social big data is being put under the computational social science microscope: about 53 million comments in 6.8 million threads, containing 2.2 billion words.
For more information please contact our contributor(s):